VOID 2022 Report Now Available

One year and almost 10,000 incident reports later, the 2022 VOID Report is here! After scrutinizing an entire year’s worth of incidents one thing is crystal clear: Resilience saves time. Taking the time to understand how to better respond when something green turns red—learning from the people, the processes, and the systems—will make the next incident smoother. Because, yes, there will always be the next incident.

Facebook, WhatsApp, AWS: How to prevent the software outages that threaten the services we rely on
The internet stood still when Facebook, Instagram, and WhatsApp or Amazon Web Services went down for hours. That may have seemed like a minor inconvenience to American users of those services. Elsewhere, it crippled essential communication for billions of people across the world. Commercial software is the engine that powers many parts of our lives. Recent outages show that […]
The VOID Podcast #2: Reddit and the GameStop Shenanigans
At the end of January, 2021, a group of Reddit users organized what’s called a “short squeeze.” They intended to wreak havoc on hedge funds that were shorting the stock of a struggling brick and mortar game retailer called GameStop. They were coordinating to buy more stock in the company and drive its price further […]

More Reports on Near Misses, Please
The final pattern we’ll cover is the lack of “near miss” incident reports. We classify a near miss as an incident that the organization noted had no noticeable external or customer impact, but still required intervention from the organization (often to prevent an actual public incident from eventually happening). As of today, there are only nine near-miss reports in the VOID—not even a half of a percent of the total entries. While this isn’t a surprising aspect of the reports in the VOID, we call it out here as an important opportunity to establish a baseline and track how it changes over time.

Root Cause Is for Plants, Not Software
Roughly a quarter of the VOID incident reports (26%) either identify a specific “root cause” or explicitly claim to have conducted a Root Cause Analysis (RCA). We consider these data preliminary, however, given the incomplete nature of the overall dataset. As we continue to add more reports, we’ll track this and see if it changes.
We’re specifically looking into RCA because, like MTTR, it is appealing in its decisiveness and apparent simplicity, but it too is misleading.

MTTR is a Misleading Metric—Now What?
Software organizations tend to value measurement, iteration, and improvement based on data. These are great things for an organization to focus on; however, this has led to an industry practice of calculating and tracking Mean Time to Resolve, or MTTR. While it’s understandable to want to have a clear metric for tracking incident resolution, MTTR is problematic for a couple of reasons.

Answering the Unanswered: The VOID Podcast
Whenever we read a company’s public incident report, there are so many questions that ultimately go unanswered. As most people familiar with incident management and analysis know, there’s plenty of information that doesn’t make it into the public writeups of a software incident.
So we thought: what if we could ask the people involved in those incidents to take us back to their experience, and answer some of those unanswered questions? That’s the idea behind the VOID podcast.
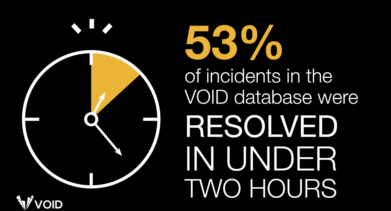
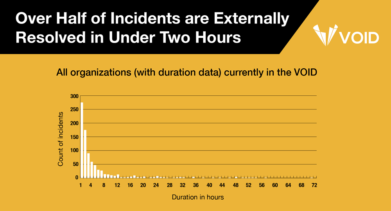
Experts Win the Day (most of the time)
When it comes to outages, we only seem to hear the bad news. In reality, the people who run these systems resolve these issues fairly quickly the majority of the time. They know this, but we haven’t had the data to show this, until now. This finding, that over half of software-related incidents are resolved in under two hours, comes from the Verica Open Incident Database (VOID). The VOID makes public software-related incident reports available to everyone, raising awareness and increasing understanding of software-based failures in order to make the internet a more resilient and safe place.
Announcing the VOID
The potential for catastrophic outcome is a hallmark of complex systems. It is impossible to eliminate the potential for such catastrophic failure; the potential for such failure is always present by the system’s own nature. Richard Cook, How Complex Systems Fail Today, we’re announcing a project that represents a small step on a long road […]

A Day in the Life: Tiffany Knudtson
I’ve been friends with James [Wickett] and his wife for a while and he asked me if I would be interested in the role. I worked with James at one of my previous jobs around 10 years or so ago, so I knew that I liked working with him and that he was a really good guy. I was able to trust that what he said about Verica was legit. He said the people here were smart and caring, and that it wasn’t a culture that beat you down. There are a lot of those types of cultures in workplaces today, but Verica is a place that you could feel like you’re being built up. I really like that. It’s a great place to work. I was saying the other day that even if I were to win the lottery, I’d still want to work here.

A Day in the Life: Karthik Gaekwad
Karthik Gaekwad Austin, TexasAt Verica for: 8 months Ed Note: This is an ongoing series about what a day in the life of various Verica folks looks like. In this post, we chat with Karthik, one of our engineers on the Kubernetes module team. In addition to being Verica’s resident Cloud Native expert, Karthik is an […]

Four Prerequisites for Chaos Engineering
Ed note: This post presumes you have some familiarity with Chaos Engineering, and are considering whether you can start experimenting with it at your organization. If you’re not familiar with Chaos Engineering, here’s a great post to get you up to speed. Chaos Engineering is often characterized as “breaking things in production,” which lends it […]

A Day in the Life: Chantell Nichols
This is an ongoing series about what a day in the life of various Verica folks looks like. In this post, we chat with Chantell Nichols, a Senior Software Engineer on the Platform team. Chantell is a dedicated teammate with an attitude that makes everyone believe anything is possible. She has an insatiable thirst for learning that motivates and inspires everyone around her.

A Day in the Life: Randall Hansen
Randall HansenVP, User Experience “I live in the burning wreckage of Portland, Oregon”At Verica for: 2 years Ed Note: This is an ongoing series about what a day in the life of various Verica folks looks like. In this post, we chat with Randall Hansen, VP of User Experience. Randall’s super power is seeing the world […]
