


Experts Win the Day (most of the time)

Editor’s note: This is the first part of a series that will focus on each one of The VOID Report 2021 key findings. If you did not have a chance to read the report, you can read the overview and key findings in the Announcing the VOID blog post. Or email us at void@verica.io to get the full report.
When it comes to outages, we only seem to hear the bad news. In reality, the people who run these systems resolve these issues fairly quickly the majority of the time. They know this, but we haven’t had the data to show this, until now. This finding, that over half of software-related incidents are resolved in under two hours, comes from the Verica Open Incident Database (VOID). The VOID makes public software-related incident reports available to everyone, raising awareness and increasing understanding of software-based failures in order to make the internet a more resilient and safe place.
We looked at the distribution of duration data for reports that provided this information (which was about half of the total reports in the VOID). Duration in this context is calculated as the time from detection to the time that the organization considered the incident to be externally resolved or remediated. Of that subset of reports with duration data, over half (53%) indicated that the incident was externally resolved in under two hours.
An important caveat is that these data generally only reflect the public-facing aspects of incidents, and don’t encompass the total amount of time and effort required of the internal team. Additionally, like judgements of the severity of an incident, what constitutes the start and end time are negotiable and vary across organizations. We’ll discuss the limitations of these duration data in detail below, but first we wanted to look at the distribution of the data.
Our initial finding demonstrates the consistency of a positively-skewed distribution of duration within and across organizations (including the entire corpus of reports in the VOID for which we had a determined duration), a phenomenon also found by Štěpán Davidovič in “Incident Metrics in SRE: Critically Evaluating MTTR and Friends.” A positively-skewed distribution is one in which most values are clustered around the left side of the distribution while the right tail of the distribution is longer and contains fewer values.
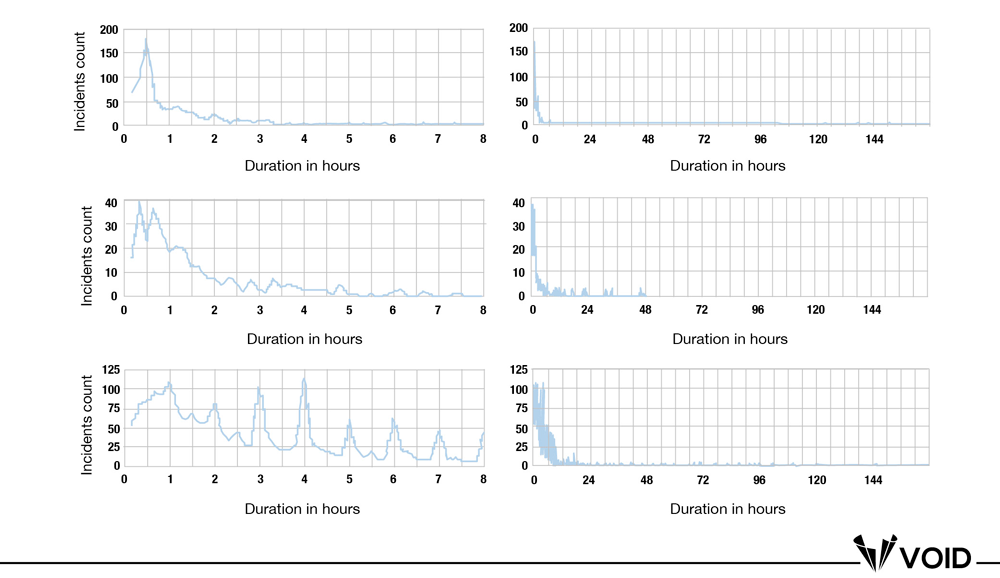
Davidovič looked at the count of incident duration for 3 companies, and each one demonstrated a positively-skewed distribution (which appeared to fit a log-normal distribution) where most incidents were resolved in under two hours.
Distribution of incidents’ durations with incident counts.
Rows are, in order, Company A (N = 798; 173 in 2019), Company B (N = 350; 103 in 2019), and Company C (N = 2,186; 609 in 2019). Columns represent each company over a short and long time frame to show the tail of the distribution. (Source: Google/O’Reilly)
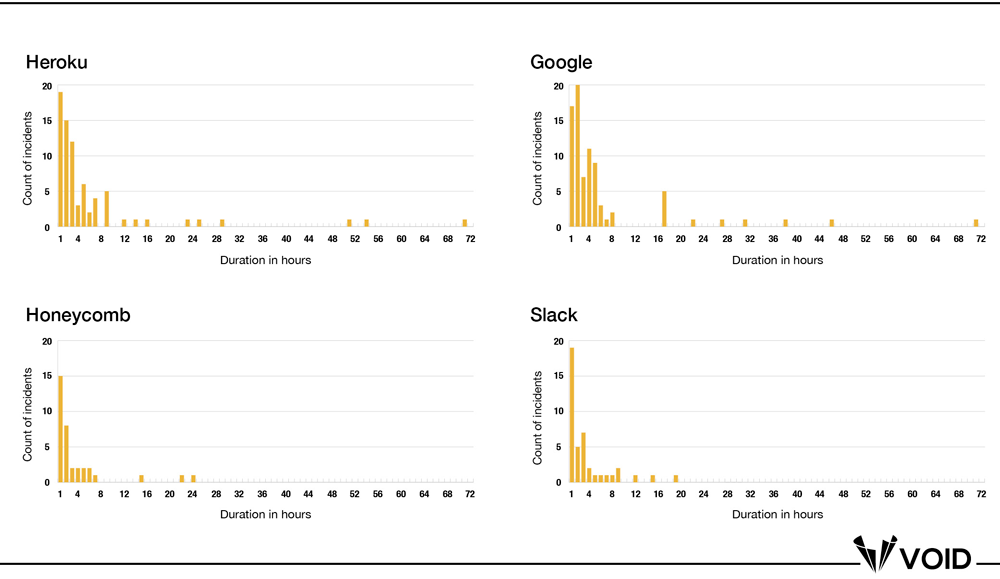
While we do not have over 100 reports for any single organization (yet) in the VOID, we were able to replicate this pattern across a number of them that had at least 40 reports:
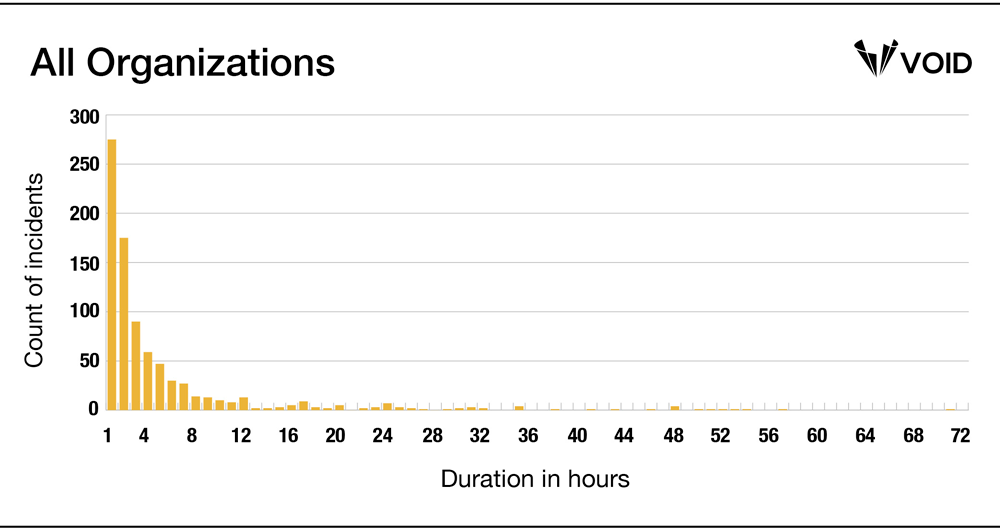
Moreover, this distribution persists even if we chart the data from every single organization, regardless of size, frequency, or total number of reports:
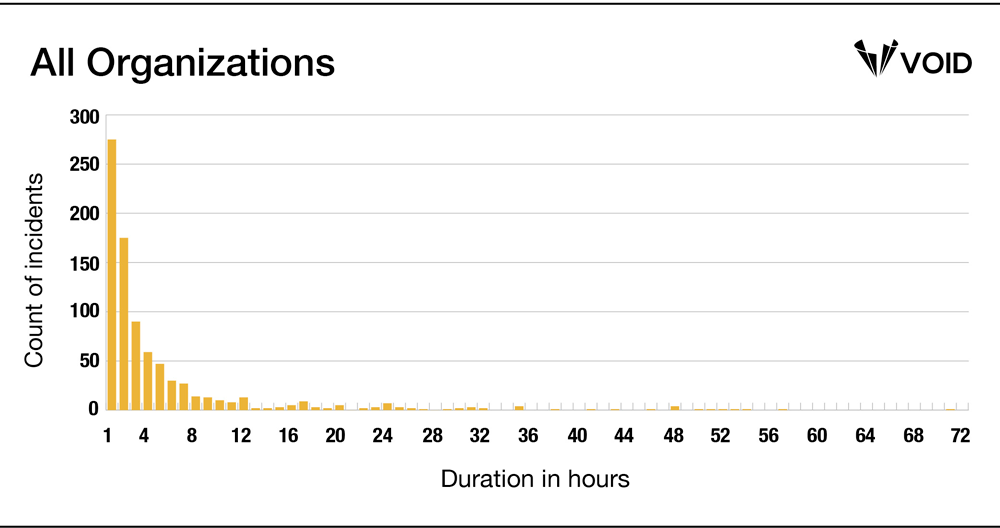
The consistency of this positively-skewed distribution across the wide variety of organizations in the VOID is noteworthy. We can’t yet say why this pattern persists, though we suspect it is likely due to standard mitigations—rolling back, reverting a bad deploy, scaling up something that is saturated, etc—working the vast majority of the time. The expertise that operators bring to bear works relatively quickly more often than not. However, there are limitations to what we can conclude from these duration data, which we will cover in our next post, MTTR is a Misleading Metric.
If you’ve found this interesting or helpful, help us fill the VOID! Submit your incidents at thevoid.community/submit-incident-report. Read more about the VOID and our key findings in the latest VOID Report.

Courtney Nash
Courtney Nash is a researcher focused on system safety and failures in complex sociotechnical systems. An erstwhile cognitive neuroscientist, she has always been fascinated by how people learn, and the ways memory influences how they solve problems. Over the past two decades, she’s held a variety of editorial, program management, research, and management roles at Holloway, Fastly, O’Reilly Media, Microsoft, and Amazon. She lives in the mountains where she skis, rides bikes, and herds dogs and kids.

Get Ahead of the Incident Curve
Discover key findings which confirm that accepted metrics for incidents
aren’t reliable and aren’t resulting in correct information.


