


Announcing the VOID
The potential for catastrophic outcome is a hallmark of complex systems. It is impossible to eliminate the potential for such catastrophic failure; the potential for such failure is always present by the system’s own nature.
Richard Cook, How Complex Systems Fail
Today, we’re announcing a project that represents a small step on a long road towards more transparency and information sharing about software-based failures and outages. The Verica Open Incident Database (aka the VOID) makes public software-related incident reports available to everyone in a single place in order to generate new, better questions and community discussion about incidents. We hope this will raise awareness and increase understanding of these types of failures in order to help make software and the internet more resilient and safer. You can read about the preliminary research results from the VOID in the 2021 VOID Report.
A Rising Tide Lifts All Boats
An organization in a competitive environment may attempt to learn from its own errors, but will try to ensure that its competitors go through the same costly trials.
Scott D. Sagan, The Limits of Safety
The VOID is something we’ve long wished already existed. Public-facing write-ups of software incidents are scattered across the internet, in scrolling status pages without the ability to link directly to them, or sequestered in corners of company websites, often in (intentionally or unintentionally) obfuscated ways. They’re hard to find, and virtually impossible to compare and contrast or study in a structured way.
Collecting these reports matters because software has long moved on from hosting pictures of cats online to running transportation, infrastructure, power grids, healthcare software and devices, voting systems, autonomous vehicles, and many critical (often safety-critical) societal functions. Software outages and incidents aren’t going to magically stop. We can’t make our systems “flawless” or systematically map out all the potential faults. What we are building now far outmatches what any single person, team, or organization can mentally model regarding how the system is built, much less how it functions in varying, high-pressure, or otherwise unexpected conditions. On top of that, customer/user and organizational demands are only accelerating the pace and complexity of software development.
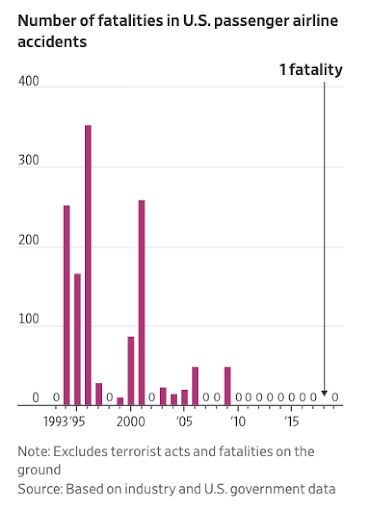
Why should we share this information? It can keep us ahead of the potentially catastrophic consequences of a software-driven world. You might be skeptical, but there’s a strong parallel from another safety-critical industry: aviation. In the mid-1990s, the U.S. aviation industry had a terrible number of fatal crashes. In 1996, U.S. carriers had a fatal accident of almost one crash for every two million departures, and more than 350 people died in domestic accidents that year alone. A multi-disciplinary group of insiders took it upon themselves to start sharing information, building a new safety-focused and data-driven approach that transformed the industry from the inside out. As a result, since 2009 there has not been a single fatal crash on a domestic flight (one fatality in 2018 stemmed from an engine fan blade coming apart during a 2018 flight). In this excellent Wall Street Journal exploration of that safety revolution, Andy Pasztor details the daring and unusual idea behind the group’s efforts:
The astonishing safety record in the U.S. stems most of all from a sustained commitment to what was at first a controversial idea. Together, government and industry experts extracted safety lessons by analyzing huge volumes of flight data and combing through tens of thousands of detailed reports filed annually by pilots and, eventually, mechanics and air-traffic controllers. Responses led to voluntary industry improvements, rather than mandatory government regulations.
Pasztor retells how “a small band of senior federal regulators, top industry executives and pilots-union leaders… teamed up to launch voluntary incident reporting programs with carriers sharing data and no punishment for airlines or aviators when mistakes were uncovered.” The results were remarkable:
You may be thinking to yourself, “Well, okay fine but my company only does [foo] and it really isn’t safety-critical, so why should we do this?” While many of us have gotten used to software taking an ever growing place in our lives, it may be less obvious the extent to which it has become safety-critical. Slack and Microsoft Teams are used for coordination and communications in emergencies unrelated to the software industry; Facebook, Twitter, and other social media are fundamental to public policy; malfunctioning developer toolchains can take down entire industries; and a global pandemic has made virtual communication tools central to global economies.
Modern online systems are expected to run 24 hours a day, 365 days a year. These increased pressures—combined with software models of interrelated, increasingly automated services that run in the cloud—have accelerated the complexity of these systems. Incidents arise from software systems that are inherently complex sociotechnical systems—they comprise code, machines, and the humans who maintain them. The humans operate via their own mental models of an environment shaped by multiple competing pressures, many of which are completely invisible. Given the complexities of and pressures on these systems, it is impressive that the vast majority of the time, they function effectively. Yet as any operator knows, they do fail, and often in unexpected and unusual ways. And now, these failures affect us all.
Much the same way airline companies set aside competitive concerns in the late 90s and beyond, the tech industry has an immense body of commoditized knowledge that we could be sharing in order to learn from each other and push our industry forward (while making what we build safer for everyone). The good news is that this is already underway for software: the Learning From Incidents community (started by Nora Jones, CEO of Jeli) provides a community of technologists, researchers, and related practitioners to share their expertise and experience related to failures and incidents related to software. LFI is reshaping how the software industry thinks about incidents, software reliability, and the critical role people play in keeping their systems running. The VOID is a direct result of having participated in this space, and owes a great deal of thanks to everyone who helped shape and inform its creation and mission.
Learning From Incidents
Incident analysis is not actually about the incident, it’s an opportunity we have to see the delta between how we think our organization works and how it actually works.
Nora Jones, CEO of Jeli
Anyone who has ever been involved in an incident that was written up and published knows that what’s in a public incident report isn’t the whole story. The notion of a “whole story” isn’t even truly possible—we can’t have perfect knowledge of a past event, and other factors like time or organizational pressures and priorities mean that at some point, an investigation has to be concluded and written up. More often than not, a public incident report exists more to assuage customer or shareholder concerns than to convey concrete details of what happened and what the team or organization learned. And it’s the latter part that really matters. As John Allspaw says in his post on this topic, when it comes to the internal version of an incident report, “The purpose of an (effective) internal write-up is to represent the richest understanding of the event for the broadest possible audience of internal, hands-on staff so that they may benefit from the experience.”
In contrast, most incident reports—notably external, or public-facing ones—focus on action items and ensuring that “this won’t happen again.” But what about the next unanticipated event? That’s typically what defines this type of software failure, it is unexpected and surprising. The past event’s action items may or may not prevent the next one. (Even if they do, teams likely won’t notice events that don’t happen.) What can help is for the team(s) that operate those systems to further evolve their understanding of how those systems work, and most critically, what their safety boundaries are.
In her keynote talk at DevopsEnterprise 2021, Nora Jones (CEO of Jeli and founder of LFI) pointed out that without making efforts to try to improve incident reviews, we’re actually not going to improve incidents on any level. People won’t update their mental model of their system if they are just checking off to-dos from the last incident and then moving on. Her emphasis on the organization is important. These systems that experience failures are ultimately sociotechnical systems comprising complex interactions between humans and machines/technology, but most reports treat them as solely technical systems. Outages result from systems that are built, maintained, and fixed by people. “Our Kuberenetes cluster fell over” is likely only part of a larger story that often involves competitive and organizational pressures that lead to trade-offs in systems where complex failures inherently lurk.
The 2021 VOID Report
Methodology
The VOID contains more than just standard company post-mortems or status updates. Because we aim to support a broader understanding of how individuals, companies, media, and others treat these types of events, it also contains blog posts, tweets, conference talks, media articles, and the occasional government report.
Along with links to the reports, we collected a set of meta-data collected directly from the language in each incident report, including:
- Date of incident
- Date of report
- Duration (if possible)
- Type of incident (full production outage, degraded performance, data loss, etc.)
- Technologies involved (if noted)
- Type of report (status page, post-mortem, blog post, media article, etc.)
- Analysis method (Root Cause, Contributing Factors, other)
In the inaugural 2021 VOID report, we analyzed a subset of the meta-data across the existing set of incident reports, including duration, analysis method, and near miss reports. Below is a summary of the results, you can email us at void@verica.io to get the free report for the full details.
Key Findings
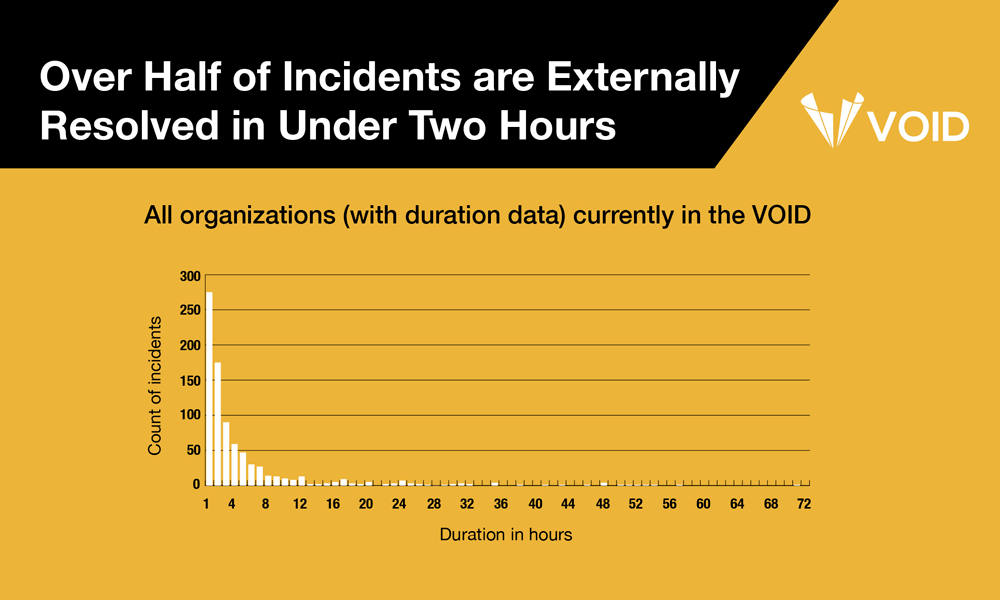
1. Over Half of Incidents Are Externally Resolved in Under Two Hours
We looked at the distribution of duration data for reports that provided this information (which was about half of the total reports in the VOID). Duration in this context is calculated as the time from detection to the time that the organization considered the incident to be either resolved or remediated. Of that subset of reports with duration data, over half (53%) indicated that the incident was externally resolved in under two hours.
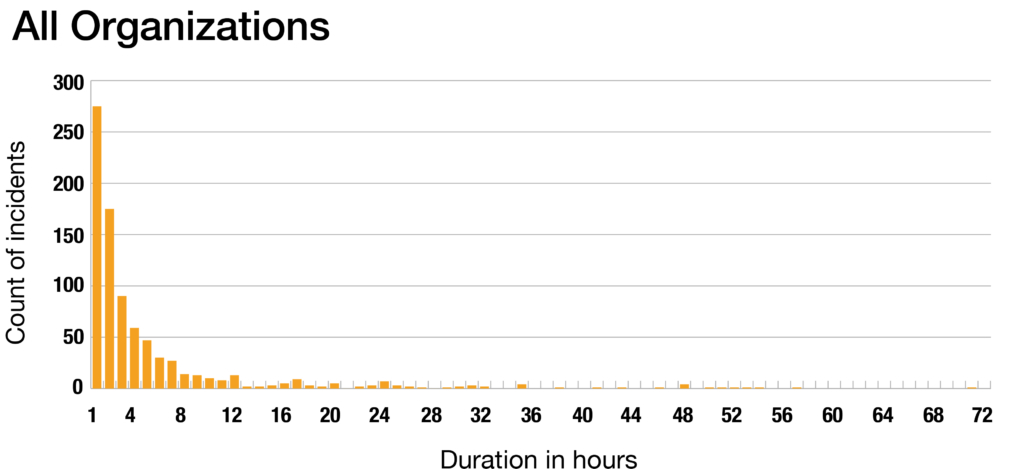
The consistency of this positively-skewed distribution—where most values are clustered around the left side of the distribution while the right tail of the distribution is longer and contains fewer values—across the wide variety of organizations in the VOID is noteworthy. We can’t yet say why this pattern persists, though we suspect it is likely due to standard mitigations—rolling back, reverting a bad deploy, scaling up something that is saturated, etc.—working the vast majority of the time.
2. Mean Time To Resolve (MTTR) is a Misleading Metric
Based on the distribution of the data we see in the VOID, measures of central tendency like the mean, aren’t a good representation of positively-skewed data. The mean will be influenced by the skewed spread of the data, and the inherent outliers. We reference research by Google engineer Štěpán Davidovič, which demonstrates that central tendency measures of incident duration are inherently too noisy to be measures of success at incident response. The report discusses other approaches and metrics that teams will want to consider instead.
3. Root Cause Analysis is Rarely Used
We were surprised to find that only about a quarter of the reports in the VOID follow some form of Root Cause Analysis (RCA), or at least explicitly identify a “root cause” of the incident. This approach is recommended and followed by large technology organizations like Google and Microsoft, hence we expected it to be more prevalent. We are interested in RCA because, like MTTR, it is appealing in its decisiveness and apparent simplicity, but it too is misleading and can foster a culture that focuses more on attribution of cause (which in some cases blames the humans in the systems) and less on understanding how the system ended up failing. In this section we analyze a set of RCA reports that include a host of latent contributing factors that combined, led to the incident in question.
4. Nearly No Near Misses in the Dataset
A near miss is an incident that the organization noted had no noticeable external or customer impact, but still required intervention from the organization (often to prevent an actual public incident from eventually happening). As of today, there are only 7 near-miss reports in the VOID—not even a half of a percent of the total entries. We’re interested in near misses because they’ve provided a rich dataset of learning opportunities for the aviation industry as they sought to improve their safety ratings; we suspect the same will apply for software. Near miss reports often include much richer information about sociotechnical systems, including breakdowns in communication, dissemination of expertise, and cultural or political forces within those systems. In the absence of external impacts, they also tend to avoid hunting for cause or blame, which provides more neutral territory for introspection and assessment of organizational knowledge gaps and misalignments.
Help Us Fill The VOID
Our goals are to:
- Collect as many public-facing reports as possible in the VOID so it becomes a reliably comprehensive resource and a unique source for researchers to ask more and better questions.
- Encourage companies that aren’t yet doing so to write detailed incident reports (and submit them).
- Raise the quality and detail of these reports industry-wide.
You can help!
Add Reports
The VOID includes everything from tweets to status page updates, conference talks, media articles, and lengthy company post-mortems. Nearly all the information comes directly verbatim from the report artifacts themselves, along with a set of metadata that we’ve collected based on the report contents. Yet we know that what’s currently in the VOID isn’t even close to the total amount of public incident reports out there. We’d love your help in making it more comprehensive. You can submit any that aren’t included in the VOID with this short form.
Become a Partner
Partners help fund the development, research, and dissemination of knowledge generated from the VOID, as well as providing advice on the ongoing direction of the program.
Subscribe to the Newsletter
The newsletter will look at patterns, stories from people involved in incidents, and other details of interest to people who care about software-based incidents.
Send Us Feedback and Ideas
Something amiss with a report in the VOID, or a bug with the VOID itself? Have an idea for a great feature or something you’d like to see that isn’t there? Get in touch, we’d love to hear from you. You can also follow the VOID on Twitter.

Courtney Nash
Courtney Nash is a researcher focused on system safety and failures in complex sociotechnical systems. An erstwhile cognitive neuroscientist, she has always been fascinated by how people learn, and the ways memory influences how they solve problems. Over the past two decades, she’s held a variety of editorial, program management, research, and management roles at Holloway, Fastly, O’Reilly Media, Microsoft, and Amazon. She lives in the mountains where she skis, rides bikes, and herds dogs and kids.

Get Ahead of the Incident Curve
Discover key findings which confirm that accepted metrics for incidents
aren’t reliable and aren’t resulting in correct information.


