


Understanding Kafka’s Consumer Group Rebalancing

The Kafka producer-cluster-consumer system is a great way to funnel high volumes of messages with spectacular reliability and order from place-to-place within your product’s architecture. However, it isn’t without its drawbacks. As with any system, some of those drawbacks are by circumstance while others are by design. The protocol for reassigning topic partitions when a consumer client fails is one of the latter. The default partition distribution protocol is intentionally designed to balance the consumption of data across available consumers. In the event that one or more consumers fail, the default rebalance protocol results in a momentary interruption of service on the side of data consumption while partitions are reassigned to the consumers that remain. This can result in a lag between the data available on a given topic and the data seen and consumed by the end clients. That lag can become a considerable problem when network reliability or consumer application reliability aren’t relative guarantees.
Let’s take a minute to understand the fundamentals of Kafka rebalancing before discussing what you can do to avoid this pain in your system architecture.
Kafka Rebalancing Fundamentals
Your standard Kafka arrangement will include some number of producer clients that send messages to partitions on a topic on some cluster, with those messages being consumed by some consumer clients. The cluster itself will consist of a number of broker servers that host the topic’s partitions and their replications. For a more concrete mental picture, let’s assume the following conditions:
- Two producer clients are sending messages to the same topic named verica-topic. For clarity we can assume that the messages are sent to topic partitions in a round-robin scheme.
- Three consumer clients that are part of the same consumer group are consuming messages from verica-topic.
- verica-topic has three partitions spread across three broker servers.
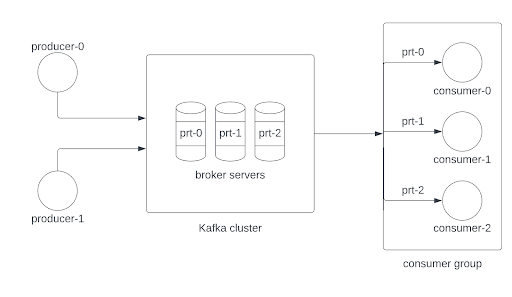
As seen in the figure above, each consumer is assigned to one of the topic’s partitions. This is a somewhat normal arrangement for Kafka.
In the course of messages flowing to and from the cluster, there may be an event that knocks one of the consumers out of communication with the broker servers, and so also with the consumer group coordinator that lives within the cluster. Such an event could include but not be limited to:
- Some network partition
- A consumer is properly unsubscribed from the topic
- A consumer hasn’t polled the topic for a while
- An error within the consumer’s application that removes it from service
- Some latency between the consumer and cluster that extends beyond the configured consumer session timeout
Regardless of the reason, some interruption prevents the consumer from communicating with the cluster. When the consumer is unable to reach the cluster, the group coordinator will remove that consumer from the consumer group. This process will kick off a rebalancing event, where the remaining consumers will be relieved of their partitions and the group coordinator will re-distribute the topic’s partitions to the remaining consumers. During this time, the remaining consumers within the same group will not be able to continue consumption until the rebalancing event completes. Our example above would then look like this:
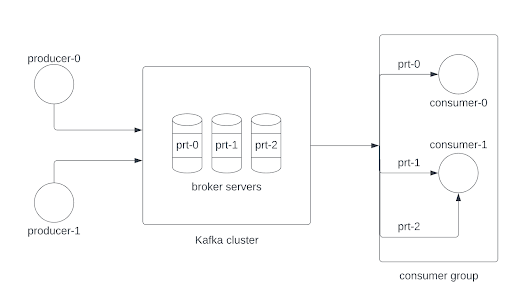
A rebalance event has no effect on the producers that push to the topic; they continue to send messages as long as there are messages to be sent. Once the partitions have been redistributed, the consumers will resume from the offset where they left off on each of their assigned partitions. For the newly-assigned partition, the consumer that picked up the slack will use the last committed offset from the ejected consumer as its offset reference.
Kafka Rebalancing Consequences
1. Consumption fully stops while the consumer group rebalances the partitions.
You may have applications on the consumer side of a given Kafka arrangement that are dependent on the stream of messages coming from the cluster. They will experience an interruption and subsequent lag between the latest messages consumed from the topic and the most recent messages available within the topic.
2. If the consumer failure is transient and it rejoins the group when it’s next available, there will be a new rebalance event.
Rebalance events don’t only happen when a consumer leaves the group. When a “new” (from the perspective of the group coordinator) consumer joins the consumer group, that’s another rebalance event.
3. Failures can happen at any time, even during a rebalance event.
Kafka’s rebalance protocol can fail for a number of reasons. Kafka does contain configurable retry logic, and even backoff times between retry attempts. However, these don’t guarantee that your consumer group will resume consumption—a persistent failure that occurs during a rebalance will just stop consumption. Period.
4. The rebalance duration scales with the number of partitions.
During a rebalance event, every consumer that’s still in communication with the group coordinator must revoke then regain its partitions, for all partitions within its assignment. More partitions to manage means more time to wait as all the consumers within the group take the time to manage those relationships.
What Can You Do?
There are measures that can be taken to reduce the number of rebalance events, but there is nothing you can do to ensure that they never happen again while still maintaining reasonably-reliable consumption. One of those measures is taking advantage of Kafka’s static group membership, which was made available as of Apache Kafka 2.3. This is the group.instance.id setting for consumers, set uniquely on each consumer within a group.
The idea behind static group membership is that while a consumer lives as part of a consumer group, the individual consumers within the group take on static IDs. Then, if a given consumer restarts or dies entirely, the rebalance event gets tied to whether or not its unavailability exceeds the session timeout (which should be long if using the static group ID), rather than whether or not its individual heartbeat isn’t detected within a shorter time period. Consumption on its partition assignments is paused (since it’s the only consumer to which those partitions are assigned), but if it rejoins before the session timeout with the same static ID then consumption just resumes. If it doesn’t rejoin in time then a rebalance event occurs as usual.
Another possibility is to enable the incremental cooperative rebalance protocol instead of the default “stop the world” protocol. With incremental cooperative rebalancing (set on the consumers’ configuration as partition.assignment.strategy: ”cooperative-sticky”), available for consumers as of Apache Kafka 2.4, instead of stopping all consumption to accommodate the necessary rebalancing due to the loss/gain of a consumer, partition assignments are redistributed incrementally to the available consumers. What this means is that when a consumer is lost (beyond session timeout), only its partitions get revoked instead of all partitions being revoked from all consumers. Then the group leader assigns the revoked partitions incrementally to the remaining consumers while allowing other consumers to continue consuming. This change in rebalance protocol is beneficial when only a small number of consumers relative to the size of the group are lost—more consumers lost means more interrupted service for remaining consumers.
Hope Is Not A Strategy
Kafka is a sophisticated system for organizing large volumes of messages from a variety of publishers to a variety of subscribers, however its potential for complexity can often cause pain. The rebalance protocol is built into Kafka, so it’s no use hoping it never bites you in the ass. Luck will not be in your favor. Instead, you can seek to understand this complex system, learn why it does what it does, and implement these newer Kafka features to mitigate potential service loss within your Kafka architecture.
Request a demo to discover how Verica’s Kafka Verifications can work for you to proactively discover Kafka weaknesses and failures before they happen.

If you liked this article, we’d love to schedule some time
to talk with you about the Verica Continuous Verification Platform
and how it can help your business.

Nicholas Hunt-Walker
Prior to life as an engineer, Nicholas spent 10 years as an astronomer, using Python to process vast amounts of data from a variety of sky surveys. Since switching over to software, he’s found his fulfillment in tech education and involvement with the Seattle Python meetup group, Puget Sound Programming Python (aka PuPPy). He’s at his best when he’s teaching others how to do things, and as such has given talks on web development and building familiarity with cloud infrastructure with the intent of illuminating for others what he’s been able to learn himself.


